
2024 年的最后一个月,全球 AI 圈好像约好了,一起开启年底狂卷模式,批量发布新品。
据 " 四木相对论 " 统计,这场年末上新的 " 战局 ",至少有 15 家全球 Top 级 AI 公司参与,上新了 20+ 个功能。
 在海外,最受关注的无疑是 OpenAI 开启 12 天大放送,期货 Sora 终于兑现。
在海外,最受关注的无疑是 OpenAI 开启 12 天大放送,期货 Sora 终于兑现。
差不多同期,Google、xAI、World Labs、Meta、Amazon、Pika、Runway 等海外名企也都上新了 AI 功能。
国内的 12 月,大厂、六小虎和 AI 鲶鱼 DeepSeek,无一不踏入战局。
" 卷王 " 字节首当其冲。它在豆包和即梦中上新了图像理解能力。
六小虎中的 MiniMax、阶跃星辰、智谱 AI,有的卷模型,有的卷 Agent 应用。Deepseek 和腾讯直接上新并开源了模型。
整体来看,各大公司近期的更新呈现以下特点:
视觉能力和生产力场景是两大主题;
80% 以上的更新都围绕 " 视觉 ";
可协作、可编辑是产品层更新的方向;
解析理解能力依旧是模型层的重点。
但卷归卷,不少产品也出于缺乏曝光等因素,发布得 " 悄无声息 "。
还有些万众期待的产品,比如 Sora,收获了满屏差评。
在这个轰轰烈烈的 12 月,目前你记住了谁?
海外:OpenAI 挤牙膏,其他家无人 care?
在这个 12 月,已经加入 AI 上新战局的海外公司至少有 OpenAI、Google、xAI、Meta、Amazon、Pika ……
 " 营销专家 "OpenAI 的声势最大。
" 营销专家 "OpenAI 的声势最大。
12 月 6 日,它拉开了 " 双十二 " 的阵仗,要连做十二场发布会。
目前日程已经进入到第七天,发布成果如下:
Day1:发布 o1 正式版以及 o1 Pro 版本,以及 200 美金的 ChatGPT Pro 会员。
Day2:介绍强化微调(Reinforcement Finetuning)功能,即通过少量数据让模型在专业领域到达专家水平。
Day3:Sora 登场,接入了新模型 Sora Turbo 的 Sora,最高上限支持生成 1080p、20 秒视频,支持横屏竖屏各种常见尺寸。
Day4:发布生产力工具 Canvas,该功能允许用户与 ChatGPT 合作写作和编码。
Day5:ChatGPT 融入苹果生态。
Day6:三个功能发布:实时视频通话、实时理解屏幕、圣诞老人限定语音。
Day7:推出了 Projects In ChatGPT 功能,可以将 ChatGPT 的各种功能整合至一处,便于用户创建并管理各类项目。
不仅是 OpenAI,Google、Pika、Midjourney、xAI 也在这周有了新动作。
12 月 14 日,Pika 上新模型 2.0,引入场景元素(Scene Ingredients)功能。
这一功能允许用户自由选择角色、物品、服装和场景元素,根据需求构建特点镜头。同时, Pika 2.0 支持多人在同一画布上协作。

 12 月 12 日凌晨,谷歌发布了 Gemini2.0,声称"Gemini2.0 是我们迄今为止最新、功能最强大的 AI 模型。"
12 月 12 日凌晨,谷歌发布了 Gemini2.0,声称"Gemini2.0 是我们迄今为止最新、功能最强大的 AI 模型。"
这一模型可以支持图片、视频和音频等多模态的输入和输出,速度也是 1.5Pro 的两倍,还能直接调用 Google Search、代码执行等工具。
在 Gemini2.0 架构之上,谷歌还推出或升级了三个新的 AI Agent 原型:通用大模型助手 Project Astra、浏览器助手 Project Mariner、编程助手 Jules。
 不过,Gemini2.0 的声量相较于 Sora 小得多。
不过,Gemini2.0 的声量相较于 Sora 小得多。
几乎在官宣之后不到半小时,Gemini 2.0 词条的热度在 Twitter 上就已经掉到了第 8。在不断下降的过程中,网友们还在分享 Sora 的鬼畜视频,以及 Hunyuan、Hailuo、Kling 与 Sora 的能力对比。
这可能也是因为 Gemini 2.0 的更新虽然好评很多,但从表述上看起来很 " 常规 ":更快速的响应、支持联网搜索、新上线的 " 深度研究 " 功能支持多轮复杂推理、代码生成增强、第三方工具调用能力补充。
同一天,Midjourney 官宣了 patchwork 功能更新。
这是一个允许多人在线共同创建出一个世界的实验性功能,所有参与者将在一块白板画布上共同创作(有点像 Canva 和 Figma 的共同编辑)。
 而且画布还给每个用户的世界创建了一个传送门,可以连接到别人的世界中。
而且画布还给每个用户的世界创建了一个传送门,可以连接到别人的世界中。
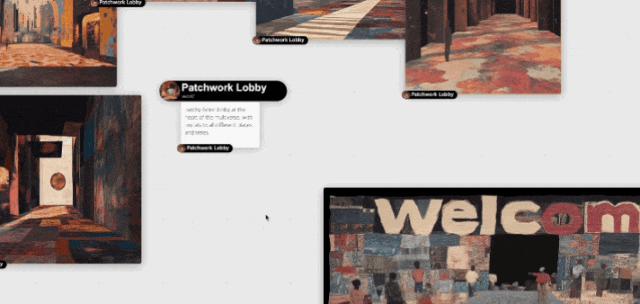 之前 Midjourney 的更新基本都围绕着图片生成的能力,比如支持 AI 修图、支持新画风的模型等等。
之前 Midjourney 的更新基本都围绕着图片生成的能力,比如支持 AI 修图、支持新画风的模型等等。
但这次的 Patchwork 让 MJ 在玩法上有了大不同,从一个只能一个人用的图片生成工具,变成了一个可以让大家一起玩起来的 AI 艺术创作产品。
手握巨卡的 xAI,同样在卷视觉方向。
12 月 10 日,xAI 发布了首款完全自研图像生成模型 Aurora。
Aurora 已经直接集成到了 Grok 中,这是一个自回归混合专家模型(MoE),在混合文本和图像数据集上完成了训练。除了图片生成,Grok 还有编辑能力,用户可以直接在生成的图像上进行修改,这一功能也将上线 X。
 Meta 也在 12 月 7 日发布了 Llama 3.3,在性能上开卷。据说现在 70B 的版本就能实现以前 405B 的性能。
Meta 也在 12 月 7 日发布了 Llama 3.3,在性能上开卷。据说现在 70B 的版本就能实现以前 405B 的性能。
它在指令遵循(IFEval)、数学(MATH)、推理(GPQA Diamond)等领域的水平都超过了七月份发布的 Llama 3.1 405B。在语言(MMLU)、代码(HumanEval)、长文本和多语种能力上,它的成绩也和 Llama 3.1 405B 比较接近。
官方将 Llama 3.3 的进步归功于新的对齐过程和在线强化学习技术的进步。
Runway 则在前一天,也就是 12 月 6 日更新了自己的 act-one 功能。这个新功能允许用户将自己拍摄的表演动作或声音直接 " 套用 " 到已有的视频角色上(包括 AI 角色)。
在 12 月最早打响发布 " 竞赛 " 的其实是 "AI 教母 " 李飞飞。
12 月 3 日,李飞飞创立的 World Labs 首次官宣了 " 空间智能 " 模型,利用一张图就能生成一个 3D 世界。
这些 3D 场景都能在浏览器中实时渲染,还能实现可控的相机效果,可调节的模拟景深。
 也是在同一天,亚马逊对外发布了多模态模型 Nova 系列。
也是在同一天,亚马逊对外发布了多模态模型 Nova 系列。
亚马逊这次直接发了一个大号全家桶,包括:超快速文本生成模型 Amazon Nova Micro,能够处理文本、图像和视频并生成文本的多模态模型 Amazon Nova Lite、Amazon Nova Pro 和 Amazon Nova Premier,用于生成高质量图像的 Amazon Nova Canvas 和用于生成高质量视频的 Amazon Nova Reel。
 不管这一波海外的年底上新如何轰轰烈烈,看起来,很多人只关注了 Sora。
不管这一波海外的年底上新如何轰轰烈烈,看起来,很多人只关注了 Sora。
好吧,OpenAI 的营销又赢了。
国内:六小虎大厂混战视觉
相比海外,国内厂商们的 " 卷 " 势更早出现。各家的方向从模型卷到产品,离不开视觉和生产力两个话题。
" 四木相对论 " 也对近半个月的新品进行了汇总:
 在大公司里,字节和腾讯是 12 月最卷的大厂(通义千问在 11 月 28 日发布了 QWQ 模型)。
在大公司里,字节和腾讯是 12 月最卷的大厂(通义千问在 11 月 28 日发布了 QWQ 模型)。
在这个 12 月,前者在豆包和即梦上先后更新功能,后者一下子开源了视频生成模型。
先看字节。
12 月 10 日,豆包官方表示,电脑版的视频生成功能已经开启内测。
获得内测资格的账号每日可免费生成十支视频。内测申请通过后,选择 " 视频生成 " 功能,上传一张图片,输入提示词,并添加运镜、分镜信息,就能生成短视频。
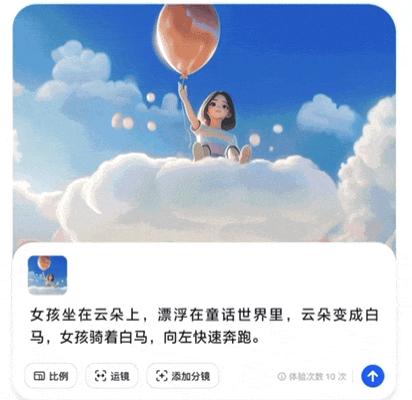 再往前的 12 月 5 日,豆包增加了 AI 生成文字图功能。也就是说,用户现在可以在提示词中加入文本要求,生成带有指定文字的图片,做海报、做表情包都能用。
再往前的 12 月 5 日,豆包增加了 AI 生成文字图功能。也就是说,用户现在可以在提示词中加入文本要求,生成带有指定文字的图片,做海报、做表情包都能用。
 (四木用豆包做的图,强调了 " 四木厨房 ")
(四木用豆包做的图,强调了 " 四木厨房 ")
类似的功能还体现在即梦上。
12 月 2 日晚,即梦上新 2.1 模型。这次的模型突破体现在中文文字可以稳定生成,当然也支持英文。
 腾讯混元这个月最大的动作,就是正式上线视频生成能力。
腾讯混元这个月最大的动作,就是正式上线视频生成能力。
12 月 3 日,腾讯不仅上线了这个 130 亿参数的模型,还把它开源了。
目前,模型已上线腾讯元宝 APP,用户可在 AI 应用中的 "AI 视频 " 板块申请试用。企业客户通过腾讯云提供服务接入,API 同步开放内测申请。
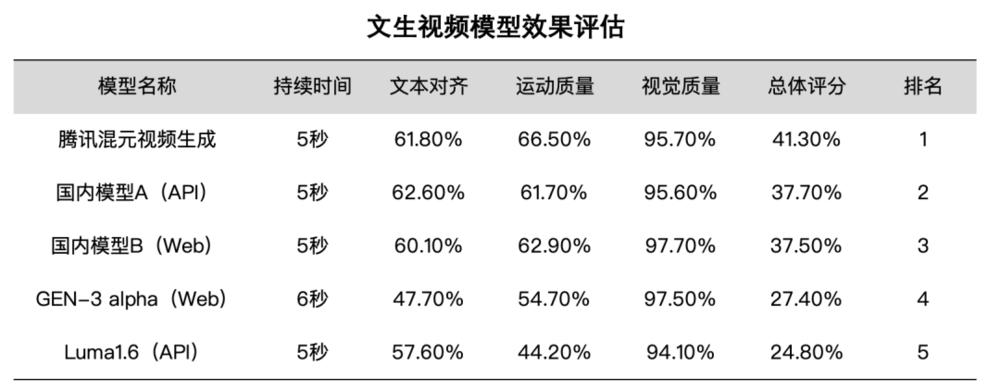 " 四木相对论 " 观察到,腾讯混元系列模型在这两个月动作比较频繁。
" 四木相对论 " 观察到,腾讯混元系列模型在这两个月动作比较频繁。
11 月初,它宣布最新的 MoE 模型 " 混元 Large" 以及混元 3D 生成大模型 "Hunyuan3D-1.0" 正式开源。12 月又上新文生视频能力,正式加入了卷视频模型的队列。
大厂之外,大模型六小虎中的三虎——智谱 AI、MiniMax 和阶跃星辰也在本月上新。
先来看智谱。
12 月的智谱在模型和应用两端发力。首先是多模态模型—— GLM-4V-Flash 上线了智谱的开放平台,可以免费调用。
GLM-4V-Flash 模型拥有图像描述生成、图像分类、视觉推理、视觉问答(VQA)以及图像情感分析等图像处理功能。
多模态 / 视觉类的 API 都非常贵,号称视觉能力对标 GPT-4o mini 模型的 GLM-4V-FlashAPI 免费,也称得上是真卷。
 产品方面,Auto-GLM 是智谱近期的重点。
产品方面,Auto-GLM 是智谱近期的重点。
首先智谱在 11 月 29 日发布了 Auto-GLM 的手机版和电脑版。半个月之后的 12 月 12 日,Auto-GLM 又更新了一个版本。
用户打开 AutoGLM 后,可以通过语音发指令,让智能体接管自己的手机,并在可操作的 App 上自动执行购买外卖,订高铁票、目的地导航等任务。
经过 " 四木相对论 " 测试,更新之后,Auto-GLM 支持的应用更稳定。同时它还增加了自定义高频短口令,快速触发常用任务等功能。
智谱 CEO 张鹏在发布会现场的 AI 发红包操作一度刷屏," 四木相对论 " 也复刻成功了。
Minimax 同样在这个月卷起了多模态。
12 月 3 日,海螺 AI 图生视频模型 I2V-01-Live 上线了。
视频生成一定是 MiniMax 今年的亮点之一。之前,MiniMax 的亮点几乎全部集中于 Talkie,但海螺视频的上线打破了这一印象。
这次的 I2V-01-Live 更新了二维插画的动态呈现方式,让动画稳定性和细腻表现力有了增强。一张图 + 一句话就能将 2D 插画转化为动态视频。

 一直略显低调的另一只小虎阶跃星辰也有模型层的更新。
一直略显低调的另一只小虎阶跃星辰也有模型层的更新。
周五(12 月 13 日)阶跃星辰发布了端到端语音大模型—— Step-1o 。
从官方介绍来看,Step-1o 支持语音、文本等混合形式的输入和输出,能理解和模仿音色、韵律、方言、个性化的口语表达习惯等声音特征。它还能够通过自学和模仿不断提升回复质量,提供解决问题的专业建议。
从场景上看,它支持包括新闻播报、聊天陪伴、有声读物、在线教育、智能硬件、汽车等语音交互技术需求。
近期,Step-1o 还将接入跃问 App 端,实现实时语音通话服务。
国内 AI 圈另一无法忽视的角色—— DeepSeek,在短短半月内进行了两次上新。
最新开源的 DeepSeek-VL2(12 月 13 日发布)是一个专家混合(MoE)语言模型。
DeepSeek-VL2 比一代 DeepSeek-VL 多一倍优质训练数据,引入梗图理解、视觉定位、视觉故事生成等新能力。视觉部分使用切图策略支持动态分辨率图像,语言部分采用 MoE 架构低成本高性能。
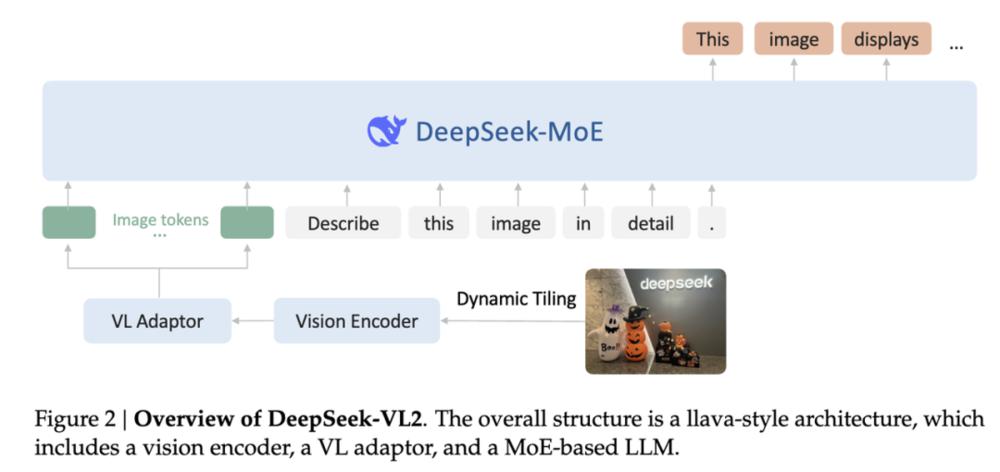 这次,大模型价格 " 卷王 " 更是在视觉模型上开 " 卷 "。
这次,大模型价格 " 卷王 " 更是在视觉模型上开 " 卷 "。
根据 DeepSeek 提供的评测对比,DeepSeek-VL2 在相似或更少的激活参数下实现了最先进的性能。
 另外,DeepSeek V2.5 系列的最终版微调模型—— DeepSeek-V2.5-1210 也在 2 月 10 日更新。
另外,DeepSeek V2.5 系列的最终版微调模型—— DeepSeek-V2.5-1210 也在 2 月 10 日更新。
据官网介绍,这次更新通过 Post-Training 全面提升了模型各方面能力表现,包括数学、代码、写作、角色扮演等。同时,新版模型优化了文件上传功能,并且全新支持了联网搜索,可以服务各类工作生活场景。
 不同于某些 AI 公司只强调功能或者模型的偏好,这次 DeepSeekV2.5-1210 模型更新后,它的 Chat 窗口呈现出两个 Tag —— " 深度思考 " 和 " 联网搜索 "。
不同于某些 AI 公司只强调功能或者模型的偏好,这次 DeepSeekV2.5-1210 模型更新后,它的 Chat 窗口呈现出两个 Tag —— " 深度思考 " 和 " 联网搜索 "。
这似乎在告诉外界:产品日常场景和模型推理能力我全都要。真的是卷王了。
12 月才刚刚过半,接下来,AI 圈的上新还会继续。
毕竟,OpenAI 的年末发布刚刚走过一半。字节也会在下周举行大会,强调豆包、即梦的更新。
最卷 12 月,AI 永不眠。
来源:四木相对论















