从去年的“百模大战”到今年的“优胜劣汰”,AI大模型赛道呈现赛马机制,不少国产大模型以GPT-4o为标杆快速迭代,在核心能力上持续赶超。近期,由国内权威大模型评估平台OpenCompass(司南)公布的CompassArena周榜上,科大讯飞星火大模型连续三周位列前三,两次摘得第二桂冠。由于榜单采用专业用户投票方式,结合了用户对各款大模型的真实体验,更具客观性和说服力,含金量十足。
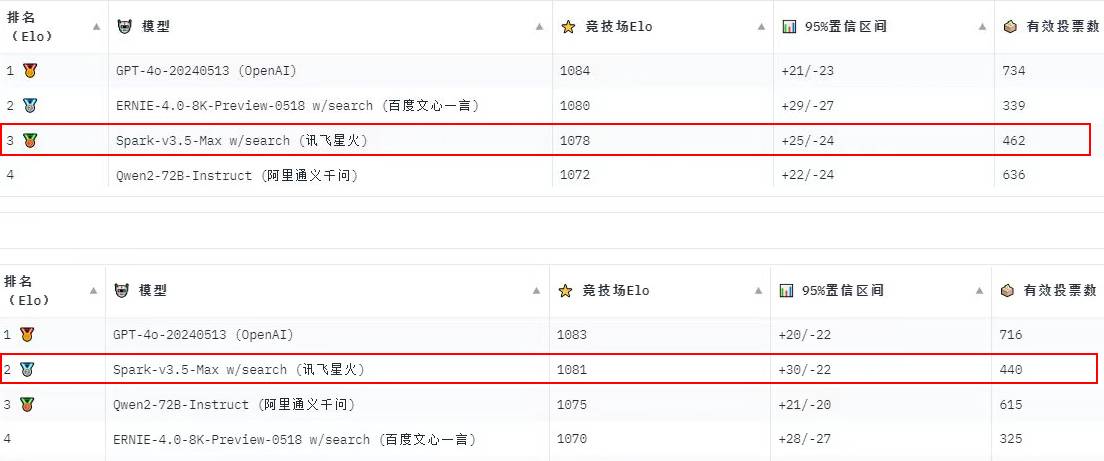
OpenCompass(司南)是由上海人工智能实验室发布的开源大模型评测体系,目前已成为业界权威的大模型评估平台,涵盖学科、语言、知识、理解、推理等评测维度,可全面评估大模型的综合能力。在最新三期专业用户投票的周榜评选中,讯飞星火以Elo-1078和Elo-1081位居前三,榜单前四强还出现阿里通义千问和百度文心一言的身影,它们共同组成了国产大模型的第一梯队,不断向榜单第一名的GPT-4o发起挑战。
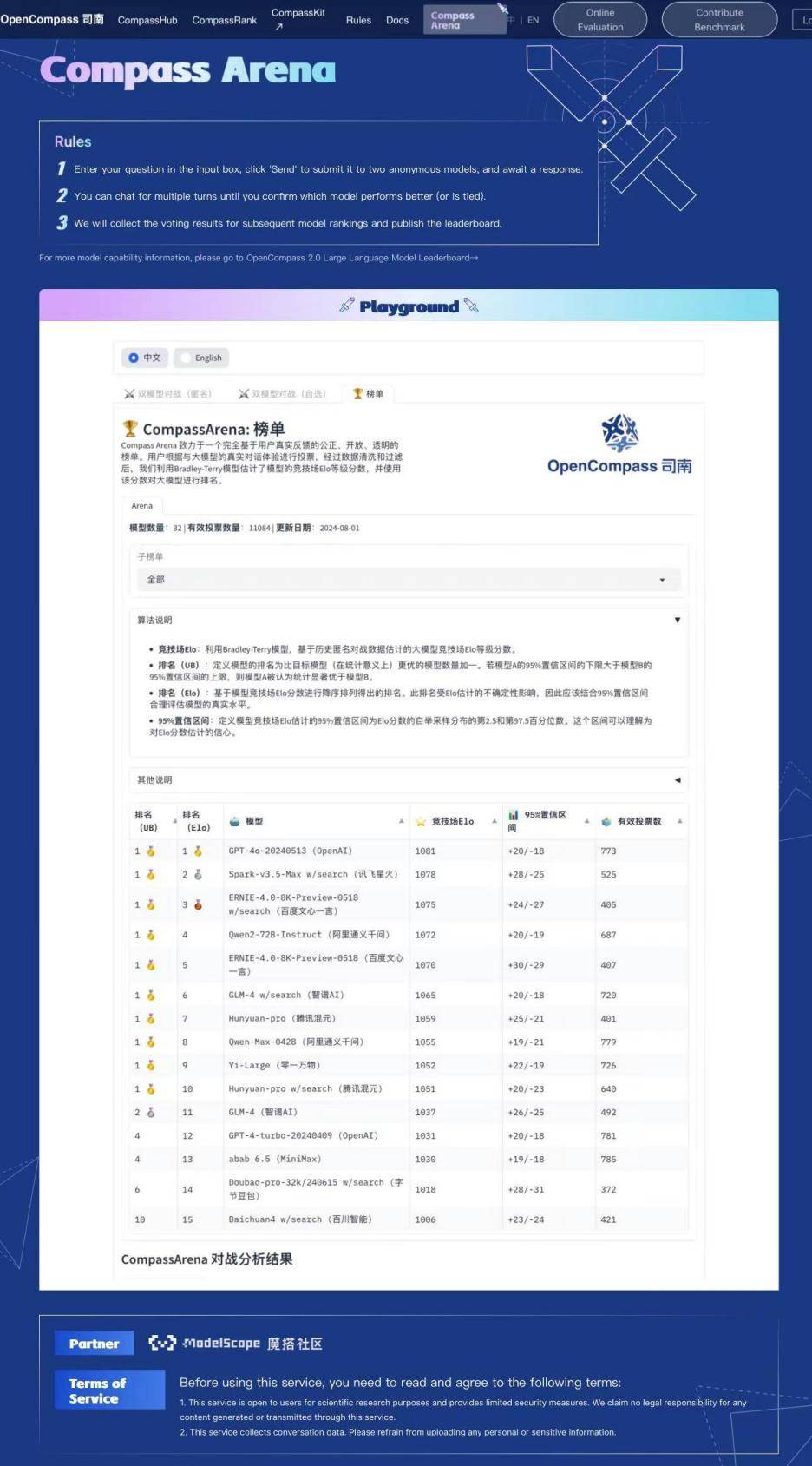
根据CompassArena榜单排名规则,平台会利用Bradley-Terry模型,基于历史匿名对战数据评估大模型竞技场Elo的等级分数,并使用该分数对大模型进行排名。最终数据可以公正、开放、透明的反映当前各家大模型产品的综合实力。
作为明确提出对标OpenAI的国内大模型公司,科大讯飞在今年6月27日发布的星火V4.0版本上,已完成了对GPT-4 Turbo的整体超越。根据八个国际主流测试集的横向评测,讯飞星火V4.0排名第一,在文本生成、语言理解、知识问答、逻辑推理、数学能力等方面完成了整体超越。这些测试集既有HumanEval、WinoGrande、GPQA等英文评测,也有C-Eval、CMMLU等中文评测,充分展现了讯飞星火的全方位实力。
此前,讯飞星火还在国际权威的《麻省理工科技评论》横评中脱颖而出,凭借领先的语言能力、数学、理综等多项核心能力,超越了同期的其它国产大模型选手,并以1013分的总分斩获国产主流大模型榜首席位。该机构还认为,讯飞星火在工作提效方面具有明显优势,是一款优秀的提效类工具。
目前,讯飞星火凭借领先技术优势和出色的体验,持续领跑国内大模型第一梯队。根据讯飞星火V4.0发布会上公布的数据,其安卓端APP的累计下载量已经高达1.31亿次,位列国内工具类通用大模型APP第一。更有大量围绕日常工作、生活与学习的实用助手“源源不断”地涌现,持续帮助用户解放生产力,释放想象力。
历经一年多迭代,讯飞星火快速成长为国内领先的大模型,对标GPT-4o的下一代版本也在研发中。随着核心能力的持续升级,讯飞星火不仅将稳居国产大模型第一梯队,更有机会成为国产大模型的代表去对战GPT-4o。















