行业主要上市公司:百川智能 ( A04400.SH ) 、昆仑万维 ( 300418.SZ ) 、拓维信息 ( 002261.SZ ) 、浪潮信息 ( 000977.SZ ) 、科大讯飞 ( 002230.SZ ) 等
本文核心数据:国内外主要大语言模型数据 ; 中外代码预训练模型对比表 ; 大语言模型研发技术国内外主要研究机构及代表性成果等
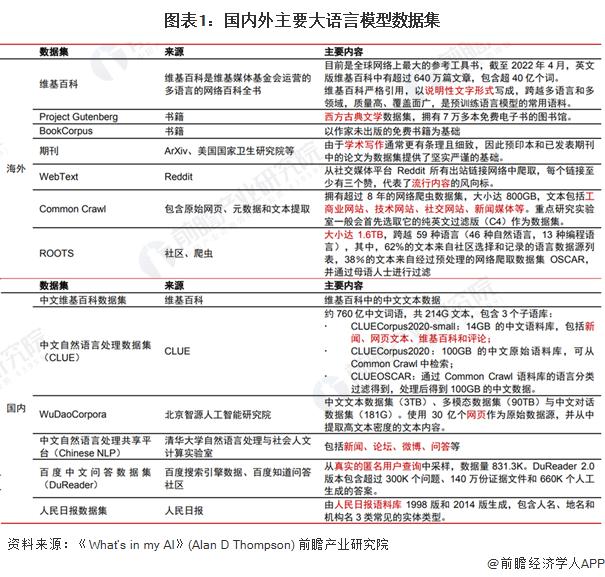
国内外主要大语言模型数据集
得益于开源共创的互联网生态,海外已有大量优质、结构化的开源数据库,文本来源既包含严谨的学术写作、百科知识,也包含文学作品、新闻媒体、社交网站、流行内容等,更加丰富的语料数据能够提高模型在不同情景下的对话能力。而受制于搭建数据集较高的成本以及尚未成熟的开源生态,国内开源数据集在数据规模和语料质量上相比海外仍有较大差距,数据来源较为单一,且更新频率较低,从而导致模型的训练效果受限。因此,大模型厂商的自有数据和处理能力构成模型训练效果差异化的核心。受益于移动互联网时代积累的海量用户、应用和数据,互联网企业在自有数据上更具特色化和独占性,叠加更强大的数据处理能力,从而能够通过数据优势带来模型训练成果的差异。例如,阿里在研发 M6 时,构建了最大的中文多模态预训练数据集 M6-Corpus,包含超过 1.9TB 图像和 292GB 文本,涵盖百科全书、网页爬虫、问答、论坛、产品说明等数据来源,并设计了完善的清洁程序以确保数据质量。百度 ERNIE 模型的训练数据集中也运用了大量百度百科、百度搜索以及百度知识图谱等生态内数据,通过更高质量的数据保障了模型的训练效果。
 代码预训练模型正成为新的热点
代码预训练模型正成为新的热点
同样,预训练语言模型就是预训练方法在自然语言处理领域中的应用,本质上是对自然语言的表示学习,是将自然语言转化为让机器可以处理的数据表达形式。预训练语言模型先通过大量的语料 ( 通常是无标注的数据 ) 进行训练,得到一个通用的语言表征模型,然后再使用面向具体任务的少量语料,就可以完成下游任务的训练。近年来,代码预训练模型正在成为一个新的热点,并且与语言大模型的发展不可分割,这些模型在代码相关任务上已经展示了出色的性能。
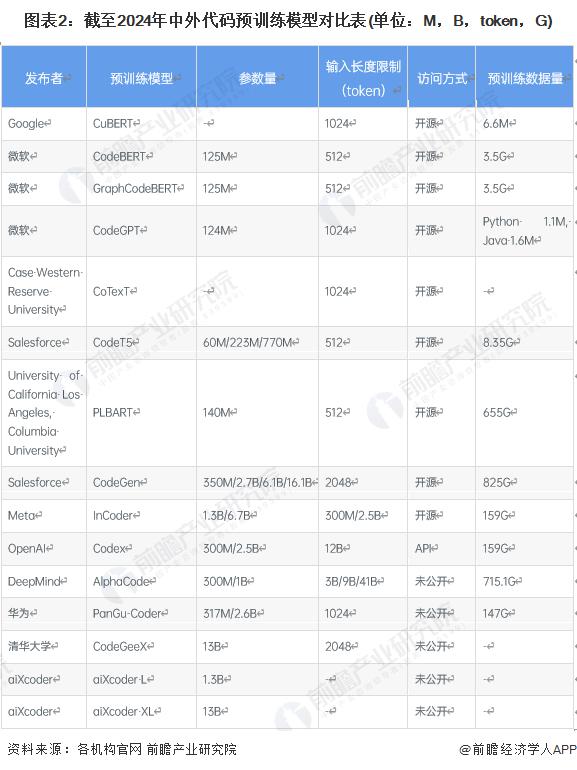 注:该图表数据截至 2024 年 1 月。
注:该图表数据截至 2024 年 1 月。
中国大语言模型研究已取得一定成果
语言大模型研发技术国内外情况差异较大,尽管国内大语言模型研究已取得了一定成果,但与美国仍然具有一定差距,尤其在端到端语言大模型研发技术,中国暂没有比肩美国的成果。
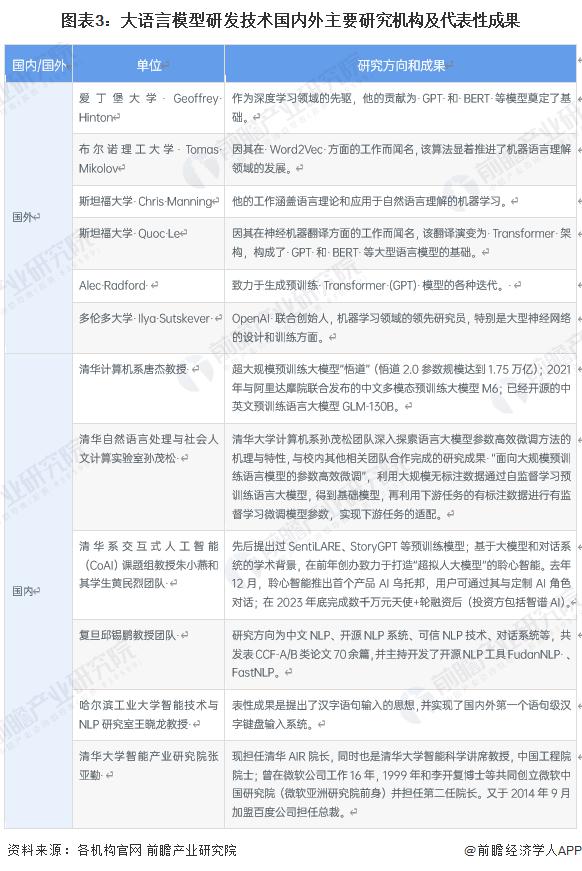 国内外主要大语言模型研发路径与技术对比
国内外主要大语言模型研发路径与技术对比
在大语言模型 ( LLMs ) 的全球竞技场中,ChatGPT 与 Google 的 Gopher、LaMDA,以及 Meta 的 Llama 等构成了国际标杆,而国内则由百度的 " 文心一言 "、360 的大语言模型、阿里的 " 通义千问 " 和商汤的 " 商量 " 等引领潮流。从对话和文本生成能力的角度,ChatGPT 暂居优势,但这并非因为技术壁垒不可逾越。实际上,Google 等国外企业因战略和技术理念选择了不同的发展路径,这是其暂时落后的主因。随着新技术的不断涌现,赶超 ChatGPT 并非不可能。相对而言,百度等国内企业在数据集、计算能力和工程化方面存在短板,短期内难以实现对国外模型的迎头赶上,这更多地需要国内 AI 产业全链条的协同进步。
在影响大语言模型性能的因素方面,训练数据、模型规模 ( 即参数数量 ) 、生成算法和优化技术被认为是核心变量。然而,如何准确量化这些因素对模型性能的具体影响,目前还处于探索阶段,没有明确的结论。总体来看,世界顶级的大语言模型在技术层面上尚未拉开明显的差距。
 国内外大语言模型商业化路径对比
国内外大语言模型商业化路径对比
在战略业务拓展方面,ChatGPT 已经形成了明确且差异化的商业路线,主要围绕 API、订阅制和战略合作 ( 例如与微软的 Bing、Office 等软件的嵌入合作 ) 三大营收模式,在用户数据积累、产品布局和生态建设等方面已具备明显的先发优势。而 Google 由于其主营业务是搜索引擎,对于聊天机器人等产品的发展相对保守,更注重利用大模型能力来推动 " 模型即服务 " 范式,以拓展其在云服务市场的份额。作为国内大模型的标杆企业,百度的战略更接近 Google,主要针对 B 端市场,通过全栈优势来构建全链能力
 来源:前瞻网
来源:前瞻网















