随着云计算产业的快速崛起,带动着各行各业开始自己的基于云的业务创新和信息架构现代化,云计算的可靠性、灵活性、按需计费的高性价比等优势已经让很多企业把“云”业务列入到未来发展战略规划中。现代化应用是现有应用程序的再升级,也是基于新技术新模式开发的新应用。现代化应用可以帮助企业面对更加复杂的业务竞争,并在这样的竞争中凭借模型的先进、数据的洞察、应用的创新实现领先。因此,许多企业希望通过采用现代应用程序开发的模式,转变应用程序的设计、构建和管理方式,从而提高敏捷性,并加快自身的创新进程。以云原生、容器、微服务、Serverless 等为基础的现代化应用开发兴起之际,各行业都把关注的目光瞄准到了数据架构上。毕竟微服务、Serverless 构建的应用就像是引擎,而数据才是真正的动力。
1.现代化应用开发之难亦是数据架构创新之难
现代化应用对规模、可用性和性能都提出了更高的要求。

对于现代化应用来说,不仅要应对剧增的用户数量,还要支撑不断增长的应用负载种类和数量。这是现代化应用开发面对的第一个难题——更强的可扩展性。
以游戏的场景为例,目前排名靠前的国民级游戏日活用户已经超过 1 亿多人,未来百万以上用户量将成为应用程序的常态,我们畅想一下最近大火的元宇宙场景,如果是一个全球级别的元宇宙应用,其用户数量会是这个数据的数倍,甚至数十倍,媲美亚马逊黑色星期五大促销的高并发情况将成为日常。所有人都在一个元宇宙进行交互的场景,对应的后端系统响应并发的要求是极高的。这不是在揣测,而是基于事实和现状,对未来的合理预测。因此首先需要解决的,就是更大规模并发问题。
现代化应用开发面对的第二个问题,是如何存储海量数据,以及存储海量数据之后,如何对这些数据进行实时化和智能化处理。
当前数据已呈现出“二八定律”:结构化数据占 20%,非结构化数据占 80%。《微软飞行模拟器》模拟真实的山脉、道路、云朵,产生了超过 2.5PB(2.5 x 10^6 GB)的结构化数据,终极元宇宙所需数据量至少比此高出多个数量级。
根据 IDC 的最新报告,现有数据中非结构化数据占比已超过 90%。随着新型软件的增多,非结构化数据占比将越来越高。不同格式、不同标准的非结构化数据在技术上比结构化数据更难存储和分析。传统数据架构应对这样的海量数据将会很吃力。
另外,现代化应用还需要考虑性能和延迟的问题。未来,新的现代化应用都会以遍布全球的用户为目标,这就对延迟有极高的要求。在游戏中,10ms 的延迟都是不可接受的,有些游戏甚至需要内存级别的延迟。超强的带宽、超快的传输速度等的实现,需要遍布全球的通信基础设施建设。
需要注意的是,在考虑高并发和低延迟的同时,还需要兼顾考虑总体质量和成本。建立、运行和维护这么大规模的应用需要耗费的人力和物力,一般企业可能难以承受。所以除了质量,成本也是需要考虑的问题。
总结来看,现代化应用至少要处理 TB 级、PB 级的结构化数据和数倍于此的非结构化数据,支持分布在全球的数百万用户,并以极低的延迟每秒处理数百万个请求。
对于非结构化数据,如今很多企业开始基于 Amazon S3 这类具备 EB 级扩展能力的云存储构建云上数据湖,并通过云原生数据分析处理工具对这些数据进行处理分析。而对于结构化数据,还需要弥补以下缺陷:
企业被传统商业数据库束缚,而难以开展创新。传统商业数据库不仅价格昂贵,还有专有技术及许可条款,需要经常进行审计。虽然越来越多的企业转向了 MySQL 和 PostgreSQL 等开源数据库,但他们仍需要商用数据库的性能;
无法满足特定场景需求。随着应用场景的不断增加,不同应用程序有了自己特定的需求。现在,开发人员越来越多地使用微服务架构来构建应用程序,并且选择新一代的关系型和非关系型数据库。但关系型数据库的结构数据耦合性大,不利于扩展分布式部署。非关系型数据库没有事务处理,复杂查询方面略微欠缺;
传统数据库运维模式仍旧需要耗费精力和成本。运维耗时但价值输出较低,但企业又不得不在这方面耗费精力和成本。
2.现代化应用需要什么样的数据架构作为支撑?
既然现有数据架构难以支撑现代化应用的实现,一场数据架构变革势在必行。这个新型数据架构要能够解决上述提到的问题,即需要拥有更高的扩展性、能够适应多样化的数据形态、有更高的数据处理能力和更低的延迟,当然还要有实现的路径和工具。
相关技术方案与创新
当下,IT 界的最佳技术组合可能就是“云计算 + 人工智能”。云计算解决了扩展性、数据存储、性能等问题,而人工智能技术则大大提高了数据分析和处理效率。
云计算可以为现代化应用的峰值需求“无限续杯”与平稳运行时的“最佳能耗”。作为云计算模型之一的 Serverless,在理论上可以自动适配应用从零到无穷大的需求峰值,更加擅长解决扩展性的问题。
Serverless 架构的好处在于可以按需加载,这样应用便不会持续占用资源,只有在请求到达或有事件发生时才会被部署和启动,避免了成本浪费。同时,Serverless 应用原生支持高可用,可以更好地应对突发的高访问量。当数据库也 Serverless 化,就可以实现高度扩展性及容量自动伸缩,做到按量付费、降低支出成本,进一步解放数据库的管理和运维。2012 年亚马逊公司推出的 Amazon DynamoDB 就是 Serverless 数据库。
2007 年,亚马逊公司发表的关于 Key-value 存储的划时代论文《Dynamo: Amazon's Highly Available Key-value Store》解决的核心诉求就是满足“永远在线”的用户体验,提升其数据库的可用性、扩展性和性能,被认为是 NoSQL 的开山之作,之后催生了一系列 NoSQL 分布式数据库。而 Amazon DynamoDB 就是 Dynamo 理念的正统实现,它正在驱动那些传统数据库难以承载的新一代高性能、互联网规模应用。
以 Serverless 数据库为代表,云数据库正在迅速发展成熟,并带来更好的可访问性和高可用性,还有高扩展性与可迁移性。此外,云数据库也降低了部署的难度和成本,不会给企业造成特别大的负担。
面对大规模数据,传统数据库组件还存在业务类型不敏感、自动运维能力弱等问题,机器学习算法可以分析大量数据记录,标记异常值和异常模式,还可以在系统运行时自动、连续、无人工干预地执行修补、调优、备份和升级操作,尽可能减少人为错误或恶意行为,确保数据库安全、高效运行。而亚马逊云科技在 re:Invent 上最新发布的 Amazon DevOps Guru for RDS 就可以帮助检测数据库问题、执行根本原因分析和推荐更改建议,甚至能够自动修复数据库问题。
现代化应用最终是面向全球的,现在很多企业也在做全球化布局。在这个过程中,全球分布式应用系统成为企业首选。分布式系统中各个节点通过一个通信网络互联在一起,不仅方便通信还可以实现资源共享,也加快了计算速度。不过,这也让企业的运维压力变大,同时存在一定的数据传输安全问题。所以,自动化的、安全的部署非常重要。
技术的选择永远伴随着一定性能的牺牲,很难有一个产品能够在性能、功能和可用性等方方面面都做到极致。传统数据库厂商“一个数据库打天下”的做法已经无法满足需要。按照不同的目的、使用场景构建不同类型的数据库产品,做到“专库专用”则是新数据架构的核心。专库专用可以适配各种不同规模的应用程序,优先提供应用程序最需要的性能,可用性大大提高。
3.如何实现架构现代化?
架构的通俗理解就是,企业可以使用现代的数据架构来摆脱传统数据库的束缚,并有专用工具来完成基础设施的现代化。当然这并不容易,很大程度上取决于厂商的能力。
根据 Gartner 2020 全球云数据库魔力象限报告,亚马逊云科技持续保持创新与领先。因此,我们以亚马逊云科技为例,看看其是如何为企业数字驱动转型助力的。
三大重要特性,两大重要支持
首先,亚马逊云科技开创了 Serverless 数据库,来实现数据库的弹性伸缩,进一步简化企业创建、维护和扩展数据库的操作。
亚马逊云科技旗下有五大 Serverless 数据库:Amazon Aurora、Amazon DynamoDB、Amazon Timestream(一种时间序列数据库服务)、Amazon Keyspaces(兼容 Apache Cassandra 的托管数据库服务)和 Amazon QLDB(一种全托管的分类账数据库)。其中,Amazon Aurora 已经进化到 v2 版本,可以在一秒内将数据库工作负载从数百个事务扩展到数十万个事务,与为峰值负载配置容量的成本相比,最多可节省 90%。
那么,Serverless 数据库的表现如何呢?华米科技健康云可以算得上是一个典型案例。截至 2021 年 2 月 2 日,华米科技智能可穿戴设备记录的累计步数为 151 万亿步,累计睡眠记录 128 亿晚,心率记录总时长 1,208 亿小时。华米科技健康云每天需要完成 TB 级数据的收集和存储,不仅需要存储的数据量巨大,同时还必须保证极高的数据安全性、稳定性和低延迟响应。为了解决这些难题,华米科技健康云使用 Amazon DynamoDB 作为核心数据库,存储用户的健康及与运动相关的数据。而 Amazon DynamoDB 在任何规模下都能提供延迟不超过 10 毫秒的一致响应时间,支持构建具有无限吞吐量和存储空间的应用程序,满足了华米健康云的数据存储需求。此外,Amazon DynamoDB 的无服务器架构使用户无需预置、修补和管理任何服务器,也无需安装、维护或运行任何软件。
目前,华米科技已经全面引入了亚马逊云科技。华米科技大数据及云平台副总裁张稷表示,“华米科技健康云在数据存储和处理方面的特点是冷热数据分层明显,数据访问的波峰波谷也很明显,亚马逊云科技丰富的功能使我们可以选用不同的服务来应对不同的需求以平衡性能与成本。”现在,华米科技使用 Amazon DynamoDB 存储核心数据;用 Amazon Simple Storage Service (Amazon S3) 存储冷数据、日志以及备份数据;用 Amazon Simple Queue Service (SQS) 、Amazon Simple Notification Service (Amazon SNS) 和 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 进行数据同步;用 Amazon Lambda 进行数据迁移和转存;用 Amazon Kinesis 和 Amazon EMR 进行大数据分析。与切换到亚马逊云科技之前相比,如今华米科技健康云的 P0 和 P1 级别故障数量大约减少了 20%,故障恢复时长减少了约 30%,总体服务可用性提升了 0.25%,系统的可用性指标达到 99.99%。
此外,九州通也使用 Amazon Aurora 替换了传统 MySQL 数据库,整体数据库性能提升了 5 倍,TCO 降低了 50%。
其次,为实现专库专用,亚马逊云科技现在已有十多种专门构建的数据库服务,囊括了关系、键值、文档、内存、图、时间序列、宽列和分类账八大数据类型。这些数据库产品各有优势,分别适用于不同的应用场景。
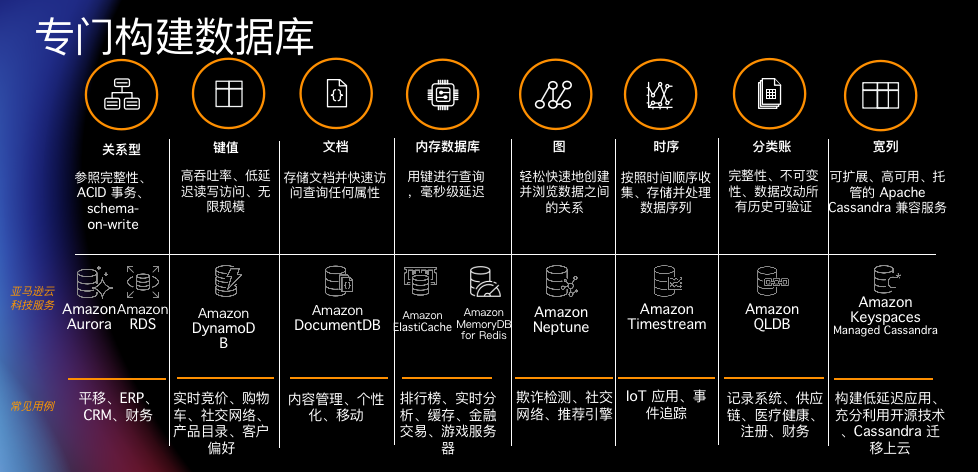
其中,Amazon MemoryDB for Redis 是一个与 Redis 兼容的、持久的内存数据库服务。它是为具有微服务体系结构的现代应用程序专门构建的, 可以用作微服务应用程序的高性能主数据库,企业不需要再分别管理缓存和持久数据库。
Amazon DocumentDB 则是一项快速、可扩展、高度可用且完全托管式文档数据库服务,支持 MongoDB 工作负载。作为一个文档数据库,Amazon DocumentDB 可以简化存储、查询和索引 JSON 数据。开发人员可以使用与今天相同的 MongoDB 应用程序代码、驱动程序和工具,来运行、管理和扩展 Amazon DocumentDB 上的工作负载,享受改进后的性能、可扩展性和可用性,而无需担心底层基础设施的管理。
Amazon DynamoDB 是为海量数据、大型混合工作负载而生的键值数据库服务,根据官方介绍,Amazon DynamoDB 可以构建吞吐量和存储空间几乎无限的应用程序,在任意规模环境中提供一致的个位数毫秒响应时间,极其适合游戏、广告技术、移动互联以及其它需要任何规模的低延迟数据访问的应用程序。虎牙已经通过 Amazon DynamoDB 自动扩容来应对 10 倍以上的流量突增。
众所周知,NoSQL 很多时候是在做“大力出奇迹”的事情,即通过大量的冗余存储 + 索引实现快速访问,但是这也有可能造成存储空间的浪费。而在亚马逊云科技 re:Invent 大会上正式发布的 Amazon DynamoDB Standard-Infrequent Access (DynamoDB Standard-IA),在保持同样性能、耐用性和伸缩性的同时,最高还可以为使用者节省 60% 的存储空间。
再者,亚马逊云科技的数据库服务与人工智能技术深度集成。亚马逊云科技的 Amazon Aurora ML、Amazon Neptune ML 等服务,支持数据库开发者在不具备机器学习专业知识情况下,只需使用熟悉的数据库查询语言(比如 SQL)即可进行机器学习操作。
我们不得不谈的是云数据库在提供数据存储服务于应用之后的价值, 实现统一分析和利用机器学习进行业务创新,助力企业数据驱动的业务转型。像亚马逊云科技提出的“智能湖仓架构”实现的是通过一系列的服务,允许数据库,数据仓库以及各种分析工具之间的数据无缝流动,同时在数据库内提供直接开始机器学习的能力, 让 DBA、数据库工程师也能很快利用机器学习来进行业务创新而不是关注技术学习, 这都是云数据库的优势。人工智能平台公司启元世界使用了“智能湖仓”进行云上创新,实现了数据的融合和统一治理,加快了其全生命周期产品矩阵理念的落地和规模发展。同时,对流数据处理系统实现了分钟级部署,并能够轻松承载百万 QPS(每秒查询率)流数据,还将批处理运行时间减少 80%,运营总成本下降 50%。
另外,为支持企业的全球分布式应用系统,亚马逊云科技推出了 Amazon Aurora Global Database(全球数据库)、Amazon DynamoDB Global Tables(全局表)、Amazon ElastiCache for Redis Global Datastore(全局数据存储)、Amazon DocumentDB Global Clusters(全局集群)等功能,企业可以一键配置现有集群,本地写入数据全球可读,并享有亚毫秒级延迟能力。
根据 CAIDA 统计,亚马逊云科技也是全球大的互联网带宽拥有者之一。亚马逊云科技全球所有的区域、可用区和边缘节点之间,均通过跨越大洲和大洋的高带宽冗余光缆连接,并 100% 加密。据悉,亚马逊云科技的基础设施遍及全球 25 个地理区域的 81 个可用区(AZ)。
最后,制定迁移计划对企业来说可能是一项挑战。为此,亚马逊云科技研发了多种迁移工具,如 Amazon Schema Conversion Tool 可用于转换数据库模式、Amazon Database Migration Service (Amazon DMS)用于迁移数据,还有今年新发布的 Amazon DMS Fleet Advisor,可以用来收集分析数据库模式和对象,包括关于功能元数据、模式对象和使用情况指标的信息,并且允许企业通过确定将源数据库迁移到亚马逊云科技中目标服务的复杂性来构建定制的迁移计划。此外,刚刚在全球上线的 Babelfish for Amazon Aurora PostgreSQL 还可以帮助企业迁移到 SQL Server 应用程序。据悉,目前全球已有超过 45 万个数据库迁移至亚马逊云科技。
值得注意的是,亚马逊云科技已经成为元宇宙公司 Meta 的战略云服务提供商。Meta 将使用更多亚马逊云科技的计算、存储、数据库和安全服务,并将在亚马逊云科技上运行第三方合作应用,同时 Meta 将使用亚马逊云科技的计算服务来进行包括人工智能项目在内的相关研发工作。
此外,当下十分流行、在全球已经拥有超过 3.5 亿用户的元宇宙游戏“堡垒之夜”,其工作负载,如 3D 图像建模、实时渲染等也几乎全部都运行在亚马逊云科技的产品之上。英雄联盟的开发商 Riot 也将游戏的基础设施部署在亚马逊云科技之上。全球化运营的三七互娱也已经将一部分数据迁移到亚马逊云科技服务上,基础设施方面的压力得以大大减轻,此外,三七互娱还在亚马逊云科技的帮助下快速构建出了全球同服的云架构,使全球各地玩家都能获得几乎一致的顺畅体验。
对于这些正在构建现代化应用的企业来说,亚马逊云科技已经成为不可或缺的支撑平台。
4.结束语
Serverless、AI 赋能、专门构建、全球部署和平滑迁移这五大理念,正是亚马逊云科技“现代端到端数据战略 - 架构现代化”的内涵。
亚马逊云科技的现代端到端数据战略是一种面向未来应用的战略思考,也是一种可交付的架构,旨在为企业发展提供源源不断的动能。现代端到端数据战略主要包括三个要素:
首先是我们前文所述的数据架构现代化。架构现代化是一切创新的基石,其最重要的理念是“The right tool for the job”,即在不同的场景使用专门构建的工具,而专门的工具需要专业的现代化托管平台,这些都可以大量节省企业的时间、金钱和精力;
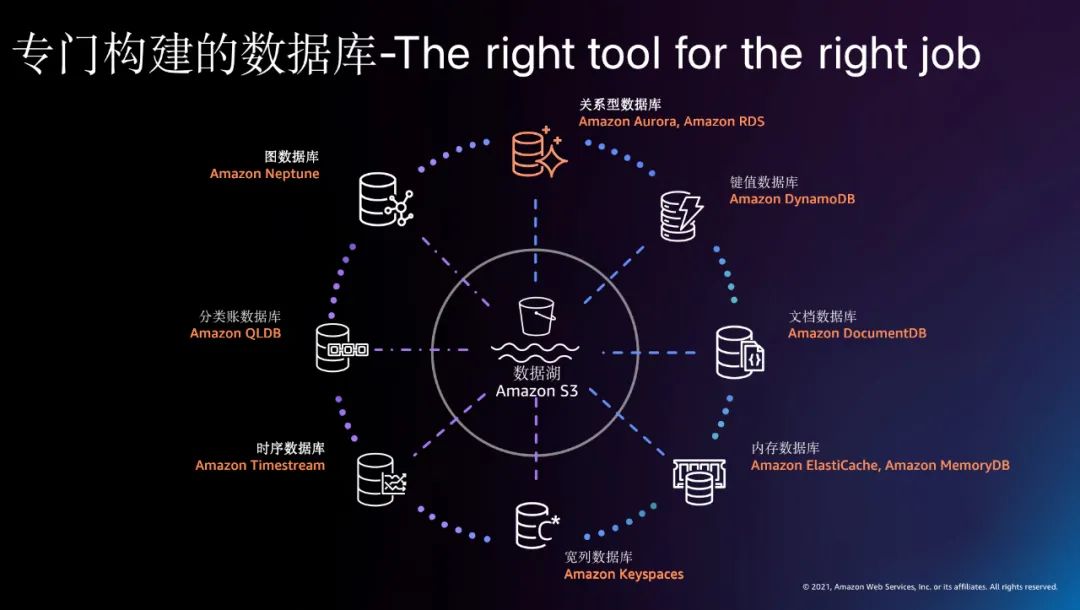
另外还有两大部分内容我们在本文没有扩展:
统一分析数据。统一分析数据则是通过云上专门工具实现数据有机整合与统一,将所有数据连接到一个安全且管理良好的连贯系统中,使企业拥有灵活扩展与极致性能。企业在获得实时反馈和数据后,可以很快地扩大服务规模;
基于数据进行业务创新。“蓬勃发展的公司与艰难求生的公司之间的关键区别在于是否将创建一个数据驱动型组织视为当务之急。”Amazon 机器学习副总裁 Swami Sivasubramanian 在亚马逊云科技 re:Invent 全球大会上说道。企业植根于自身业务的创新诉求是创新的原动力,其中训练与调优、模型部署与管理都涉及到了基础设施层面的创新。
当前企业主要面临着严重的基础设施老旧、自动化程度低和专用工具缺乏的问题,同时繁重的资本支出也阻碍了企业前进。因此,企业要做出改变的决心是很大的。Gartner 预测,到 2024 年,企业为成为数据驱动和数字化企业,将在数据和分析上增加 40% 的投入。
未来,亚马逊云科技的产品布局将进一步扩大。在现有产品基础上,亚马逊云科技将根据客户需要研发各种新产品,包括面向金融、电信、医疗和汽车等特定行业。这些都将成为企业数字驱动转型的重要利器,也会是现代化应用建设的重要基础设施。















